
Transkripsjonsretningslinjer for håndskriftsgjenkjenning
Generelle retningslinjer for transkripsjon av tekst tilpasset arbeid med håndskriftsgjenkjenning (HTR).
Håndskriftsgjenkjenning, eller handwritten text recognition (HTR), er evnen en datamaskin har til å lese håndskrift og gjøre den om til maskinlesbar tekst – som den teksten du leser nå. Maskinen må trenes på håndskrift for å bli god på å lese ulike typer dokumenter, og for å få til dette trenger vi såkalte treningsdata for å lage det vi kaller modeller. Treningsdataene består av kildetro transkripsjoner laget av mennesker, for eksempel brukere av Digitalarkivet. Disse dataene fungerer som en fasit for maskinen som skal lære å lese håndskrift. Modellen er maskinens forståelse av håndskriften, basert på disse manuelle transkripsjonene. Du kan lese mer om håndskriftsgjenkjenning på bloggen vår.
Disse retningslinjene skal du kunne følge uansett om du lager transkripsjoner i vanlige tekstbehandlingsverktøy som Microsoft Word, Pages og Google Docs, eller verktøy som er spesialisert for håndskriftsgjenkjenning, som Transkribus. Retningslinjene er best egnet for løpende tekst, men de fleste prinsippene lar seg overføre til tabeller.
Det er viktig å følge konsekvente retningslinjer når vi lager transkripsjoner som skal kunne brukes til håndskriftsgjenkjenning. De samme transkripsjonene brukes gjerne til søk og/eller visning, i tillegg til treningsdata for modeller, og retningslinjene må ta hensyn til dette.
Noen av retningslinjene innebærer bruk av spesifikke tegn til annotering/tagging – som i "%%eksempel%%" og "@@" – i de tilfellene hvor programmet du bruker ikke støtter noen annen form for annotering. Disse annotasjonene/taggene er laget slik at de ikke kan forveksles med faktisk tekst, og kan omgjøres maskinelt på et tidspunkt etter transkriberingen, slik at de ikke skaper støy i treningsdataene eller i bruken av transkripsjonene. Hvis vi er inkonsekvente i måten vi transkriberer på, vil det dermed kunne skape problemer i ettertid. Det er også derfor vi ikke kan bruke retningslinjene for avskrift og registrering som har vært brukt for blant annet kirkebøker og folketellinger, siden de ikke tar hensynene vi er avhengige av.
Nedenfor tar vi for oss de viktigste transkripsjonsretningslinjene. Jo flere av retningslinjene som følges, jo bedre blir treningsdataene. Det er likevel umulig å dekke alle eventualiteter vi kan møte på i transkriberingen her, så det sentrale er å finne en god løsning og være konsekvent med å bruke den. Spørsmål om retningslinjene kan sendes på e-post.
Kildetro transkripsjoner
Transkripsjonene skal være kildetro: Hvert tegn skal transkriberes slik det fremkommer av originalen. Dette er hovedprinsippet som alle andre transkripsjonsretningslinjer springer ut av. Dette skyldes først og fremst at håndskriftsgjenkjenningsmodeller lærer seg å transkribere maskinelt ved å se sammenhengen mellom den håndskrevne teksten og transkripsjonen vår av den. Jo likere vår transkripsjon er originalen, jo bedre treningsdata er den for modellene. Kildetro transkripsjoner, gjerne kalt faksimiliære gjengivelser, har også frem til nå vært normen ved Arkivverket av andre faglige grunner.
Vi forholder oss med andre ord til teksten slik den er i originalen. Det betyr at vi i transkripsjonen vår transkriberer alle store og små bokstaver, alle tall og alle andre tegn, som aksenter, punktum, komma og så videre, slik de fremkommer av originalen. Vi skriver for eksempel ikke ut forkortelser, forkorter ikke ord og fraser som er skrevet ut, standardiserer ikke datoer og navn, omgjør ikke tall til bokstaver eller bokstaver til tall, retter ikke feil og moderniserer ikke eldre stavemåter.
Likevel transkriberer vi med en viss velvilje hvis håndskriften er noe inkonsekvent, altså en håndskrift hvor noen ulike bokstaver kan se like ut. Hvis for eksempel skribentens o-er ofte ser ut som a-er, skal vi til tross for dette transkribere dem som "o", hvis det fremkommer av ordet at bokstaven skal være "o".
Vi transkriberer ikke innrykk eller fonter.
Legg merke til at vi behandler noen tegn på spesielle måter, særlig hvis originalteksten er av eldre dato. Les mer om dette under punktet "Spesielle tegn".
Ny linje
Vi lager en ny linje, altså linjeskift, i transkripsjonen der det er en ny linje i originalen. En ny linje lager du med enter-tasten. Dette er et av de viktigste prinsippene når vi lager transkripsjoner til håndskriftsgjenkjenning, siden feil antall linjer og nye linjer på feil sted bryter samsvaret mellom transkripsjon og original. Det vil si at antall linjer i transkripsjonen vår må tilsvare antall linjer i originalteksten, og linjene må lages der de er i originalen. Du kan lese mer om hva vi behandler som en linje under punktet "Tillegg over eller under linjen, tekst i margen og leserekkefølge".
Merk at hvis vi bruker et program som Word til å transkribere, vil teksten automatisk fortsette på neste linje når vi kommer til høyre marg. Dette teller ikke som en ny linje, og er kun noe Word gjør automatisk for syns skyld, avhengig av størrelsen på skriften og margen. Den eneste måten å lage en ny linje på i transkripsjonen vår, er å trykke på enter-tasten.
Vi følger altså originalens linjeskift i transkripsjonen, men merk at vi ikke transkriberer innrykk.
Sidereferanse
En tekst er ikke bare delt opp i linjer, men også i sider. Hvis vi for eksempel bruker Transkribus, deles transkripsjonen automatisk opp etter antall skannede bilder. Hvis vi derimot bruker programmer som Word, er ikke dette mulig. Hvor mye plass teksten tar opp i Word, avhenger av skriftstørrelse og andre faktorer som ikke hjelper oss med å skille originalsidene fra hverandre.
I programmer som Word er vi derfor nødt til å lage en referanse som peker på sidetallet i originalen. Vi markerer starten på en ny side i originalen med sidetallet etterfulgt av tegnet ">" – uten mellomrom – på en egen linje.
Legg merke til at sidetallet vi skal forholde oss til ikke nødvendigvis er det samme som pagineringen eller folieringen i originalen, altså tallene som står øverst eller nederst på sidene. Vi regner den første siden som er skannet som side 1 og teller oppover derfra, uavhengig av nummereringen i originalen. Det er dermed rekkefølgen originalsidene er skannet i som teller.
Bøker kan være skannet én side av gangen eller to sider av gangen. Uansett regner vi én side som én side transkripsjon, og en skannet dobbeltside er med andre ord to sider transkripsjon. Det er dermed ikke alltid sånn at antallet bilder tilsvarer antallet sidereferanser. For en bok som kun er skannet som dobbeltsider, vil hvert bilde ha to tilhørende sidereferanser.
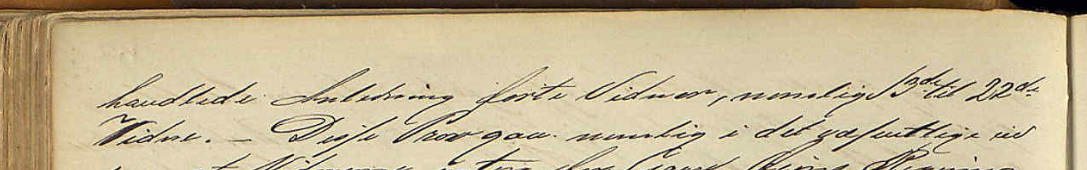
På bildet ovenfor ser vi den 151. siden i originalen, medregnet forsiden. Vi transkriberte den slik:
151>
handlede Anledning førte Vidner, nemlig 13de til 22de
Vidne.– Disse Provgav nemlig i det væsentlige eid
Vi skal ikke behandle tomme sider på noen spesiell måte. Hvis side 150 var tom, ville vi transkribert det slik:
150>
151>
handlede Anledning førte Vidner, nemlig 13de til 22de
Vidne.– Disse Provgav nemlig i det væsentlige eid
Tillegg over eller under linjen, tekst i margen og leserekkefølge
Leserekkefølgen, altså rekkefølgen en person ville lest teksten i, skal være lik mellom originalen og transkripsjonen vår. Unntaket er til tillegg over eller under linjen.
Leserekkefølgen er stort sett intuitiv for løpende tekst, men kan skape forvirring når skribenten har lagt til ett eller flere ord mellom to linjer. Kort forklart skal slike tillegg behandles som vanlige linjer, og må dermed plasseres i transkripsjonen der de er i originalen.
Tillegg over eller under linjen er gjerne rettelser eller tilføyelser til noe som allerede er skrevet. Vi skal imidlertid representere tilleggene slik de fremkommer av originalen, i tråd med prinsippet om å være kildetro, uten å plassere teksten der den "egentlig" skulle vært.
I eksempelet nedenfor skal derfor tillegget plasseres i transkripsjonen mellom linjen som er over og under i originalen.

Vi valgte å transkribere det slik:
5 Smaae Karmer med Vinduer i blye ind-
tækt med torv, og een liden boed i gaarden
fattet, tækt med bord, af Ejeren opgivet for
Det samme prinsippet om leserekkefølge gjelder transkribering av kommentarer og annen tekst i margen. Denne teksten skal transkriberes som egne linjer, og plasseres i transkripsjonen der det ville vært naturlig å lese dem i forhold til resten av teksten.
I eksempelet nedenfor er tallet "50" i høyremargen en sum, og tallet "87" i venstremargen et saksnummer. I praksis markerer "50" slutten på det foregående avsnittet og "87" starten på neste.

Vi valgte å transkribere dette som fire linjer i transkripsjonen:
bord, Taxeret af os for
50:
87
Ranni Michelsdr Strandbye Sy-
I eksempelet nedenfor refererer "Kj.gt 42" i venstremargen til en adresse, og hører sammen med sak 19. Margteksten står over to linjer, så det må den også gjøre i transkripsjonen vår.

Vi valgte å transkribere dette slik, med saksnummeret etterfulgt av margteksten:
19:
Kj.gt
42
Hr: Cancellie-Raad Erich Must Han-
Merk at hvis margteksten hadde vært i høyre marg i stedet for venstre, hadde vi i akkurat dette tilfellet plassert teksten på samme sted i transkripsjonen. Transkribering og plassering av tekst i margen avhenger av kontekst, og avgjørelsen må tas på bakgrunn av leserekkefølge og tekstens fysiske plassering i originalen.
Hvis noe av teksten i originalen står på skrå, er loddrett eller i det hele tatt ikke er vannrett, skal vi transkribere på vanlig måte, uten å markere at transkripsjonen var rotert i originalen.
Uklar skrift
Hvis vi har problemer med å forstå hva som er skrevet, skal vi ikke gjette, men markere det aktuelle tegnet eller den aktuelle sekvensen av tegn som uklar. Dette gjør vi ved å annotere/tagge de ordene eller tegnene det gjelder.
Noen transkripsjonsprogrammer støtter annotering av uklar tekst. I for eksempel Transkribus kan du markere og annotere de aktuelle tegnene eller ordene som "unclear". Hvis programmet du bruker ikke støtter dette – det er tilfelle om du bruker Word eller lignende program – skal du annotere ved å skrive to alfakrøller. Da transkriberer du den aktuelle delen av teksten som "@@", for eksempel:
Anette @@ Teige
Ri@@ardt
Li@@e Va@@n@@s
Legg merke til at vi ikke legger inn mellomrom før eller etter alfakrøllene når det ikke er mellomrom der i originalen.
Hvis det er flere ord eller tegn på rad som du ikke klarer å tyde, bruker du kun én annotasjon, altså to alfakrøller, for alle. Merk at det kun gjelder om de er på rad, ikke om de er avbrutt av andre tegn eller ord som du faktisk klarer å tyde, som vist i eksemplene over.
Uleselig skrift
Hvis en del av skriften i originalen er helt uleselig, for eksempel på grunn av et hull eller en blekkflekk, skal vi ikke gjette hva som kan ha stått der opprinnelig, selv om vi kan forstå hvilket ord eller hvilke tegn det er.
Noen transkripsjonsprogrammer støtter annotering/tagging av uleselig tekst. I for eksempel Transkribus kan du plassere markøren på det aktuelle punktet i teksten og legge til taggen "gap". Merk at gap-taggen representerer alle tegn som er uleselige på akkurat det stedet i teksten, og skal ikke suppleres med andre tegn for å representere det samme som gap-taggen. Hvis programmet du bruker ikke støtter denne typen annotasjon – det er tilfelle om du bruker Word eller lignende program – skal du annotere ved å skrive to ampersander. Da transkriberer du den aktuelle delen av teksten som "&&", for eksempel:
2. desember && Christiania
Gre&&he Hansen
Ha&&mer, Gj&&. &&
Legg merke til at vi ikke legger inn mellomrom før eller etter ampersandene når det ikke er mellomrom der i originalen.
Hvis det er flere uleselige ord eller tegn på rad, bruker du kun én annotasjon, altså to ampersander, for alle. Merk at det kun gjelder om de er på rad, ikke om de er avbrutt av andre tegn eller ord som faktisk er leselige, som vist i eksemplene over.
Overstrøket tekst
Hvis teksten er overstrøket i originalen, skal den også overstrykes i transkripsjonen.
Denne typen tekstformatering støttes av de fleste tekstbehandlingsprogrammer, som Transkribus og Word. Hvis den ikke støttes, skal vi annotere/tagge ved å omkranse den overstrøkne teksten i originalen med doble prosenttegn. Da transkriberer vi som i eksemplene til høyre:
Alf Han Jonsen Alf %%Han%% Jonsen
Gunhild Aaasse Gunhild Aa%%as%%se
Legg merke til at vi ikke legger inn mellomrom før eller etter annotasjonene når det ikke er mellomrom der i originalen.
Tekst som er skrevet over
Hvis noe av teksten har blitt skrevet over, skal vi som hovedregel kun transkribere teksten som er skrevet sist, altså den "øverst".
Vi transkriberer dermed som nedenfor:
nedover Hammeren
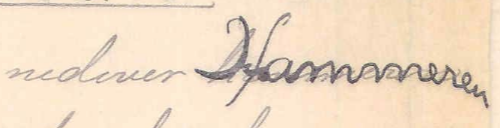
Hvis det er tydelig separasjon mellom korreksjonen og teksten som er korrigert, altså at de i liten grad overlapper hverandre, skal de transkriberes på to forskjellige linjer.
Vi transkriberer dermed teksten nedenfor slik, siden ordene er tydelig separerte:
linie tillagdes Ludvig Hansen. Grændsen paa sydsiden
nævnte
af sidstbeskrevne eiendom gaar fra havet op efter Mölneel-
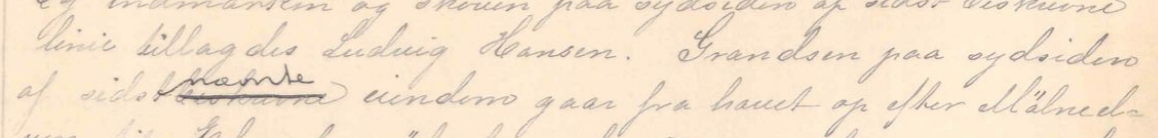
Bindestrek
Hvis skribenten skiller mellom bindestrek "-" og tankestrek "–" i egen tekst, skal vi skille mellom dem i transkripsjonen vår også. I eldre tekster kan disse komme til uttrykk som henholdsvis "=" og "–", og vi transkriberer dem gjerne som "-" og "–".
Eksemplet nedenfor transkriberer vi dermed slik:
tinglag d. aar, hvorom parterne herved gives fornöden un-
derretning.– At forretningen er utfört efter bedste skjön og i
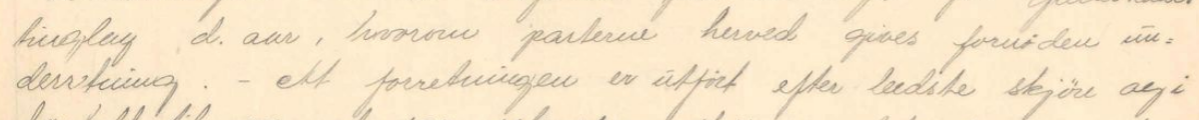
Vi transkriberer bindestreker uansett hvor de er i teksten, også om de er på starten av linjen – uavhengig av om linjen før avsluttes med en bindestrek.
Spesielle tegn
Vi forholder oss til regelen om kildetro transkripsjoner også når det gjelder spesielle tegn, så langt det lar seg gjøre praktisk.
Alle aksenter, apostrofer, tødler, komma, punktum og så videre skal transkriberes slik de fremkommer av originalen. Det finnes imidlertid to generelle unntak. Unntak én er bruk av diakritiske tegn som en del av håndskriftsstilen. To eksempler er bokstaven"y", som i gotisk håndskrift gjerne ble skrevet med tødler, "ÿ", og det å skrive "ø" som "ó". Dette regner vi altså kun som en håndskriftsstil, og vi transkriberer bokstavene som "y" og "ø". O med tødler, altså "ö", skal derimot transkriberes som "ö". Unntak to er bindestreker som skrives med "=". Disse har vi valgt å transkribere som "-".
I noen tekster kan vi støte på tegn vi ikke finner på vanlige tastatur, som gjentagelsestegnet "〃". Det er viktig at vi er konsekvente med hvordan vi transkriberer slike tegn, og de må aldri erstattes med forklarende tekst, som for eksempel "ditto" og "samme" i stedet for "〃". Tegnene vi bruker, må også være en del av Unicode-standarden.
Det er også viktig at vi bruker samme Unicode-tegn til å transkribere ulike representasjoner i originalen av det samme tegnet, så lenge det ikke finnes unike Unicode-tegn for hvert av dem. For eksempel skal gjentagelsestegnet alltid transkriberes med "〃", uansett om det i originalen ser ut som "〃" eller "—"—", fordi det ikke finnes to ulike Unicode-tegn for gjentagelsestegnet.
I eldre tekster kan noen tegn se ut som moderne tegn, men likevel bety noe annet. Som i alle andre tilfeller er det viktigste at vi da er konsekvente i transkriberingen, og at vi ikke velger retningslinjer som skaper trøbbel senere. I middelaldertekster kan vi for eksempel støte på og-tegnet "⁊", som ser ut som tallet "7". Et eksempel er og-tegnet ca. midt på bildet nedenfor, fra et diplom på latin fra 1189.

Til tross for likheten til tallet "7" ville det vært et feilsteg å transkribere det som noe annet enn og-tegnet "⁊". Tegnet betyr tross alt ikke tallet "7", og derfor gir det ingen mening å transkribere det som det.
I henhold til prinsippet om kildetro transkripsjoner skal og-tegn og ampersand heller aldri transkriberes som "og", "et" eller lignende.
Brøk
I spesielt håndskrift er det to vanlige måter å skrive brøk på: med skråstrek og med horisontal strek.
Hvis brøken er skrevet med skråstrek, for eksempel "1/2", skal vi ikke bruke noe spesielt Unicode-tegn. Vi skriver det bare med skråstrek som i det gitte eksemplet.
Hvis brøken derimot er skrevet med en horisontal strek, skal vi bruke et Unicode-tegn, for eksempel "½". Siden det finnes et uendelig antall brøker vi kan skrive med horisontal strek, finnes det ikke et eget Unicode-tegn for alle. Det vi derfor må gjøre når det ikke finnes et eget tegn, er å skille teller og nevner med Unicode-tegnet U+2044, som skrives "⁄". Ofte vil transkripsjonsprogrammet du bruker da gi brøken en egen formatering, for eksempel "24⁄25".
Eksemplet under transkriberer vi dermed slik:
1. Ditmar Arnetsens gjenværende bruk, der beholder bruksnr 2
og faar navnet Haugen at udgjöre 24⁄25 av det udelte bruk,
mark
hvorefter det faar en skyld av 1.88 og
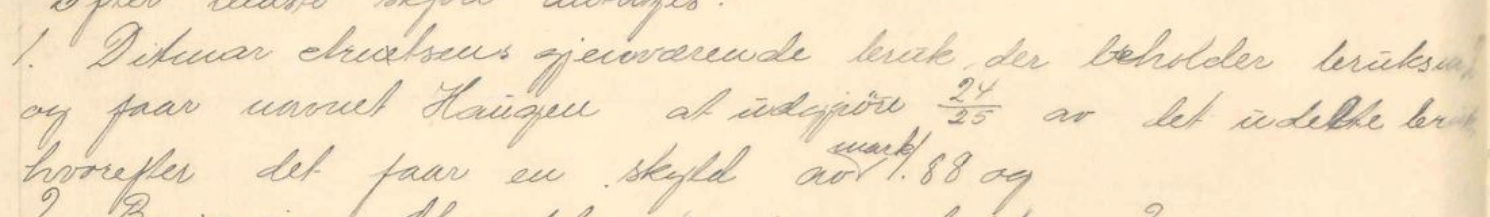
Kursiv, fet skrift og understreking
Kursiv, fet skrift og understreking er mindre vanlig i håndskrift enn i trykt skrift og maskinskrift (skrivemaskin), men kan formateres i transkripsjonen vår på samme måte som i originalen. Unntaket er skriftformen kursivskrift fra middelalderen og kursivering av egennavn i gotisk håndskrift, som vi regner som håndskriftstiler og derfor transkriberer uten kursiv.
Denne typen tekstformatering støttes av de fleste tekstbehandlingsprogrammer, som Transkribus og Word. Hvis transkripsjonsprogrammet du bruker ikke støtter formatering av kursiv, fet skrift og understreking, skal du annotere/tagge ved å omkranse den aktuelle teksten med doble henholdsvis pundtegn, eurotegn og nummertegn. Da transkriberer vi som i eksemplene til høyre:
Jorunn Steigen, syerske og pleier Jorunn Steigen, ££syerske og pleier££
1500 kr. netto 1500 kr. €€netto€€
utenfor de rammene utenfor ##de## rammene
Legg merke til at vi ikke legger inn mellomrom før eller etter annotasjonene når det ikke er mellomrom der i originalen.
Merknader av transkribenten
Transkribenten skal aldri skrive sine merknader eller kommentarer direkte inn i transkripsjonen – heller ikke med fotnoter. Hvis ikke vil kommentarene og fotnotene forstås som transkripsjoner og forstyrre treningen av modellen. Eventuelle kommentarer og andre merknader må systematiseres på en annen måte. Noen transkripsjonsprogrammer, og programmer som Word, har kommentarfunksjon, og disse kan trygt brukes, siden de ikke er en del av selve transkripsjonen.